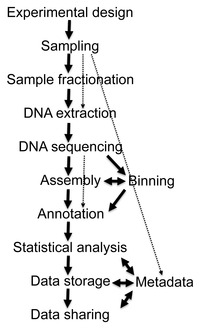
Metaxenómica
A metaxenómica é o estudo do material xenético recollido directamente de mostras ambientais. Este amplo campo pode tamén denominarse xenómica ambiental, ecoxenómica ou xenómica da comunidade.

Mentres que a microbioloxía tradicional, a secuenciación de xenomas microbiana e a xenómica dependían de facer cultivos clonais, a secuenciación de xenes ambientais inicialmente clonaba xenes específicos (xeralmente os do ARNr 16S) para obter o perfil de diversidade dunha mostra natural. Ese traballo revelou que a gran maioría da biodiversidade microbiana non se detectaba utilizando os métodos baseados no cultivo.[1]
Debido á súa capacidade de revelar a diversidade previamente oculta de vida microscópica, a metaxenómica ofrece unha potente lente para ollar o mundo microbiano que ten a potencialidade de revolucionar a comprensión de todo o mundo vivo.[2] Como o prezo da secuenciación de ADN segue baixando, a metaxenómica agora permite que se investigue a ecoloxía microbiana a unha escala e detalle moito maiores que antes. Os estudos recentes usan a secuenciación directa "de escopeta" ou a PCR para obter mostras pouco nesgadas de todos os xenes de todos os membros das comunidaes mostreadas.[3]
Termo editar
O termo "metaxenómica" foi utilizado primeiramente por Jo Handelsman, Jon Clardy, Robert M. Goodman, Sean F. Brady e outros e apareceu primeiro nunha publicación de 1998.[4] O termo fai referencia á idea de que un conxunto de xenes secuenciados a partir da nube ambiental pode ser analizado dun xeito análogo ao do estudo dun só xenoma. En 2005, Kevin Chen e Lior Pachter (investigadores da Universidade de California, Berkeley) definiron a metaxenómica como "a aplicación das modernas técnicas xenómicas sen necesidade de illar e cultivar en laboratorio especies individuais".[5]
Historia editar
A secuenciación convencional empeza co cultivo de células idénticas como fonte de ADN. Porén, os estudos metaxenómicos iniciais revelaron que propablemente hai un gran grupo de microorganismos en moitos ambientes que non se poden cultivar e, por tanto, non se poden secuenciar. Estes estudos iniciais estaban enfocados ás secuencias do ARN ribosómico de 16S, que son relativamente curtas, a miúdo conservadas nunha especie, e xeralmente diferentes entre as distintas especies. Moitas secuencias de ARNr 16S viuse que non pertencían a ningunha especie cultivada, o que indica que hai numerosos organismos que non foron nunca illados. Estes exames dos xenes do ARNr tomados directamente do ambiente revelaron que os métodos baseados no cultivo microbiolóxico atopan menos do 1% das especies bacterianas e arqueanas que realmente existen nunha mostra.[1] Gran parte do interese da metaxenómica débese a que estes descubrimentos mostran que a gran maioría dos microorganismos pasaron ata agora inadvertidos.
Os primeiros traballos moleculares neste campo foron dirixidos por Norman R. Pace e colegas, que utilizaban a PCR para explorar a diversidade das secuencias de ARN ribosómico.[6] Os coñecementos obtidos con estes avances levaron a Pace a propoñer a idea de clonar o ADN directamente de mostras ambientais xa en 1985.[7] Isto orixinou o primeiro informe do illamento e clonación de ADN en masa procdedente dunha mostra ambiental, publicado por Pace e colegas en 1991[8] mentres Pace estaba no Departamento de Bioloxía da Universidade de Indiana. Fixéronse grandes esforzos para asegurarse de que estes non eran falsos positivos da PCR e apoiaban a existencia dunha comunidade complexa de especies inexploradas. Aínda que esta metodoloxía estaba limitada a explorar xenes non codificantes de proteínas altamente conservados, apoiaba as observacións microbiolóxicas iniciais baseadas na morfoloxía que indicaban que a diversidade era moito máis complexa do que se coñecía por métodos de cultivo. Pouco despois, Healy informou do illamento metaxenómico de xenes funcionais procedentes de "zoobibliotecas" construídas a partir dun cultivo complexo de organismos ambientais cultivados en laboratorio ou herbas secas en 1995.[9] Despois de deixar o laboratorio de Pace, Edward DeLong continuou traballando neste campo e publicou traballos que puxeron os fundamentos preliminares da filoxenia ambiental baseadas nas sinaturas de secuencias do ARNr 16S, empezando coa construción de bibliotecas por este grupo a partir de mostras mariñas.[10]
En 2002, Mya Breitbart, Forest Rohwer e colegas usaron a secuenciación de escopeta ambiental (véxase máis adiante) para mostrar que 200 litros de auga de mar conteñen uns 5000 virus distintos.[11] Os estudos seguintes mostraron que hai máis de mil especies virais nas feces humanas e posiblemente un millón de virus diferentes por quilogramo de sedimentos mariños, includíndo moitos bacteriófagos. Esencialmente todos os virus destes estudos eran especies novas. En 2004, Gene Tyson, Jill Banfield, e colegas na Universidade de California, Berkeley e o Joint Genome Institute secuenciaron o ADN extraído dun sistema de drenaxe ácido de minas.[12] Esta iniciativa tivo como resultado a obtención de xenomas completos ou case completos dunha manchea de bacterias e arqueas que anteriormente se resistiran aos intentos de cultivalas.[13]
Craig Venter, comenzando en 2003, foi o líder da fundación privada que traballou en paralelo co Proxecto Xenoma Humano, e liderou a Expedición de mostras oceánicas global, que circunnavegou o planeta e recolleu mostras metaxenómicas durante a viaxe. Todas estas mostras son secuenciadas utilizando a secuenciación de escopeta, coa esperanza de que se identificasen novos xenomas (e, por tanto, novos organismos). O proxecto piloto, realizado no mar dos Sargasos, atopou ADN de case 2000 especies diferentes, incluíndo 148 tipos de bacterias nunca antes vistas.[15] Venter circunnavegou o globo e explorou exhaustivamente a costa oeste dos Estados Unidos e completou unha expedición de dous anos de duración para explorar o mar Báltico, o Mediterráneo e o mar Negro. A análise de datos metaxenómicos recollidos durante esta viaxe revelou a existencia de dous grupos de organismos, un composto de taxons adaptados a condicións ambientais de 'fartura ou fame' e outro composto por relativamente poucas taxons pero máis abundantes e amplamente distribuídos principalmente composto por plancto.[16]
En 2005 Stephan C. Schuster na Unversidade estatal de Penn e colegas publicaron as primeiras secuencias dunha mostra ambiental xerada con secuenciación de alto rendemento, neste caso a pirosecuenciación masivamente paralela desenvolvida por 454 Life Sciences.[17] Outra publicación inicial nesta área apareceu en 2006 feita por Robert Edwards, Forest Rohwer e colegas da Universidade estatal de San Diego.[18]
Secuenciación editar
- Artigo principal: Secuenciación de ADN.
A obtención de secuencias de ADN de lonxitude maior que uns poucos milleiros de pares de bases a partir de mostras ambientais foi moi difícil ata que os recentes avances nas técnicas de bioloxía molecular permitiron a construción de bibliotecas en cromosomas artificiais bacterianos (BACs), que proporcionan mellores vectores para a clonación molecular.[19]

Metaxenómica de escopeta editar
Os avances en bioinformática, os refinamentos na amplificación do ADN e a proliferación do poder computacional axudaron enormemente a análise de secuencias de ADN obtidos de mostras ambientais, o que permitiu a adaptación da secuenciación de escopeta ou shotgun ás mostras metaxenómicas (coñecida tamén como escopeta de metaxenoma completo ou secuenciación WMGS, de whole metagenome sequencing). Esta estratexia, usada para secuenciar moitos microorganismos cultivados e o xenoma humano, corta o ADN aleatoriamente, secuencia moitas secuencias curtas e reconstrúeas nunha secuencias consenso. A secuenciación de escopeta revela os xenes presentes en mostras ambientais. Historicamente, as bibliotecas de clons eran utilizadas para facilitar esta secuenciación. Porén, cos avances nas tecnoloxías de secuenciación de alto rendemento, o paso da clonación xa non é necesario e poden obterse grandes rendementos de datos secuenciados sen este paso que require un intenso traballo e supón un colo de botella no proceso. A metaxenómica de escopeta proporciona información tanto sobre que microorganismos están presentes coma sobre que procesos metabólicos son posibles na comunidade.[20] Como a obtención de ADN ambiental é en boa medida incontrolada, os organismos máis abundantes nunha mostra ambiental están moito máis representados nos datos de secuenciación resultantes. Para conseguir a alta cobertura necesaria para resolver por completo os xenomas dos membros da comunidade subrepresentados, cómpre extraer grandes mostras, a miúdo prohibitivamente custosas. Por outra parte, a natureza aleatoria da secuenciación de escopeta garante que moitos destes organismos, que doutro modo pasarían desapercibidos usando as técnicas de cultivo tradicionais, estarán representados por polo menos algúns pequenos segmentos de secuencia.[12] Unha estratexia cada vez máis usada combina a secuenciación de escopeta e a captura da conformación do cromosoma (Hi-C), que mide a proximidade de calesquera dúas secuencias de ADN nunha mesma célula, para guiar a ensamblaxe xenómica.[21]
Secuenciación de alto rendemento editar
Os primeiros estudos metaxenómicos realizados usando secuenciación de alto rendemento usaban a pirosecuenciación pyrosequencing 454 masivamente paralela.[17] Outras tres tecnoloxías comunmente aplicadas ás mostraxes ambientais son a Ion Torrent Personal Genome Machine, a Illumina MiSeq ou HiSeq e o sistema Applied Biosystems SOLiD.[22] Estas técnicas para a secuenciación do ADN xeran fragmentos máis curtos que a secuenciación de Sanger; O Ion Torrent PGM System e a 454 pyrosequencing normalmente produce lecturas de ~400 pares de bases, Illumina MiSeq produce lecturas de 400 a 700 pares de bases (dependendo de se se utilizaron opcións de extremos apareados) e SOLiD produce lecturas de 25 a 75 pares de bases.[23] [24] Historicamente, as lonxitudes destas lecturas eran significativamente máis curtas que a lonxitude de ~750 pares de bases da secuenciación de Sanger típica, porén a tecnoloxía de Illumina está aproximándose rapidamente a este punto de referencia. Porén, esta limitación compénsase polo número moito máis grande de lecturas de secuencias. En 2009, os metaxenomas pirosecuenciados xeran 200–500 megabases, e as plataformas de Illumina xeran unhas 20–50 xigabases, pero estes rendementos incrementáronse en varias ordes de magnitude nos últimos anos.[24] Unha vantaxe adicional da secuenciación de alto rendemento é que esta técnica non require a clonación de ADN antes da secuenciación, eliminando un dos principais nesgos e colos de botella nas análise de mostraxes ambientais.
Bioinformatica editar
Os datos xerados polos experimentos metaxenómicos son dun enorme volume e intrinsecamente ruidosos, xa que conteñen datos fragmentados que poden representar ata 10000 especies.[25] A secuenciación do metaxenoma do rume da vaca xerou 279 xigabases ou 279 miles de millóns de pares de bases de datos de secuencias nucleotídicas,[26] mentres que o catálogo de xenes do microbioma intestinal identificou 3,3 millóns de xenes ensamblados a partir de 567,7 xigabases de datos de secuencias.[27] A recollida, tratamento e extracción de información útil bioloxicamente a partir de conxuntos de datos deste tamaño supón retos computacionais significativos para os investigadores.[20] [28][29][30]
Prefiltrado da secuencia editar
O primeiro paso da análise de datos metaxenómicos require a execución de certos pasos de prefiltrado, como a eliminación de secuencias redundantes de baixa calidade e secuencias de probable orixe eucariota (especialmente en metaxenomas de orixe humana).[31][32] Os métodos dispoñibles para a eliminación de secuencias de ADN xenómico eucariota contaminantes inclúen Eu-Detect e DeConseq.[33][34]
Ensamblaxe editar
- Artigo principal: Ensamblaxe de secuencias.
Os datos de secuencias de ADN de proxectos xenómicos e metaxenómicos son esencialmente os mesmos, pero os datos de secuencias xenómicos ofrecen unha maior cobertura, mentres que os datos metaxenómicos son xeralmente moi pouco redundantes.[29] Ademais, o incremento do uso de tecnoloxías de secuenciación de segunda xeración con lecturas de lonxitudes curtas significa que moitos dos futuros datos metaxenomicos serán proclives ao erro. Tomados en combinación, estes factores fan que a ensamblaxe de lecturas de secuencias metaxenómicas nos xenomas sexa difícil e pouco fiable. As ensamblaxes incorrectas son causadas pola presenza de secuencias de ADN repetitivas que fan que a ensamblaxe sexa especialmente difícil debido á diferenza na abundancia relativa de especies presentes na mostra.[35] [36] As ensamblaxes incorrectas poden tamén implicar a combinación de secuencias de máis dunha especie en cóntigos quiméricos.[35]
Existen varios programas de ensamblaxe, a maioría dos cales usan información de etiquetas de extremos apareados para mellorar a exactitude das ensamblaxes. Algúns programas, como Phrap ou Celera Assembler, foron deseñados para utilizalos na ensamblaxe dun só xenoma, pero de todos modos producen bos resultados cando se ensamblan conxuntos de datos metaxenómicos.[25] Outros programas, como Velvet assembler, foron optimizados para as lecturas máis curtas producidas pola secuenciación de segunda xeración por medio do uso de gráficos de de Bruijn. O uso de xenomas de referencia permite aos investigadores mellorar a ensamblaxe das especies microbianas máis abundantes, pero esta estratexia está limitada polo pequeno subconxunto de filos microbianos para os cales están dispoñibles xenomas secuenciados.[35] Unha vez que se crea unha ensamblaxe, un reto adicional é a chamada "desconvolución metaxenómica" ou determinar de que especie procede cada secuencia da mostra.[37]
Predición de xenes editar
- Artigo principal: Predición xenética.
As tubaxes (pipelines) de análise metaxenómica usan dúas estratexias para a anotación de rexións codificantes nos cóntigos ensamblados.[35] A primeira estratexia é identificar xenes baseándose na homoloxía con xenes que están xa dispoñibles ao público en bases de datos de secuencias, xeralmente por buscas coa ferramenta BLAST. Este tipo de estratexia aplícase no programa MEGAN4. [36] A segunda estratexia, chamada ab initio, usa características intrínsecas da secuencia para predicir rexións codificantes baseadas en conxuntos de xenes de organismos relacionados. Esta é a estratexia adoptada en programas como GeneMark[38] e GLIMMER. A principal vantaxe da predición ab initio é que facilita a detección de rexións codificantes que carecen de homólogos nas bases de datos de secuencias; porén, é máis precisa cando hai grandes rexións de ADN xenómico contiguo dispoñibles para a comparación.[25]
Diversidade de especies editar

- Artigo principal: Diversidade de especies.
As anotacións de xenes proporcionan a resposta ao "que", mentres que as medidas de diversidade de especies proporcionan a resposta ao "quen".[40] [41] Para conectar a composición da comunidade e a función en metaxenomas, as secuencias deben ser agrupadas. O agrupamento é o proceso de asociar unha secuencia particular a un organismo.[35] No agrupamento baseado na semellanza, os métodos como BLAST son utilizados para buscar rapidamente en bases de datos públicas existentes marcadores filoxenéticos ou secuencias doutro modo similares. Esta estratexia aplícase en MEGAN.[41] Outra ferramenta, PhymmBL, usa modelos de Markov interpolados para asignar lecturas.[25] MetaPhlAn e AMPHORA son métodos baseados en marcadores específicos de clado únicos para estimar as abundancias relativas de organismos con desempeños computacionais melloradas. [42] Outras ferramentas, como mOTUs[43][44] e MetaPhyler[45], usan marcadores de xenes universais para facer os perfís de especies procariotas. Co perfilador mOTUs é posible perfilar especies sen un xenoma de referencia, mellorando a estimación de diversidade de comunidades microbianas.[44] Métodos recentes, como SLIMM, usan unha paisaxe de cobertura de lecturas de xenomas de referencia individuais para minimizar falsos positivos e obter abundancias relativas fiables.[46] No agrupamento baseado na composición, os métodos usan características intrínsecas da secuencia, como as frecuencias de oligonucleótidos ou o nesgo no uso de codóns.[25] Unha vez que as secuencias están agrupadas, é posible levar a cabo análises comparativas de diversidade e riqueza.
Integración de datos editar
A masiva cantidade de datos de secuencias que crece exponencialmente supón un reto desmoralizador que se complica pola complexidade dos metadatos asociados cos proxectos metaxenómicos. Os metadatos inclúen información detallada sobre a xeografía tridimensional (incluíndo a profundidade ou altura) e características ambientais da mostra, datos físicos sobre o sitio da mostra, e a metodoloxía da mostraxe.[29] Cómpre esta información para garantir a replicabilidade e para permitir unha análise augas abaixo. Debido á súa importancia, os metadatos e a revisión dos datos colaborativos e o seu tratamento requiren formatos de datos estandarizados localizados en bases de datos especializadas, como a Genomes OnLine Database (GOLD).[47]
Desenvolvéronse varias ferramentas para integrar os metadatos e os datos de secuencias, que permiten as análises comparativas augas abaixo de diferentes bases de datos usando diversos índices ecolóxicos. En 2007, Folker Meyer e Robert Edwards e un equipo no Argonne National Laboratory e a Universdade de Chicago fixeron pública a Anotación Rápida Metaxenómica usando o servidor de Subsystem Technology (MG-RAST), un recurso da comunidade para análise de conxuntos de datos de metaxenoma.[48] En xuño de 2012 foran analizadas unhas 14,8 terabases (14x1012 bases) de ADN, con máis de 10000 conxuntos de datos de acceso público libre para a comparación en MG-RAST. Uns 8000 usuarios enviaron un total de 50000 metaxenomas a MG-RAST. O sistema de Xenomas/Metaxenomas Microbianos Integrado (IMG/M) tamén proporciona un conxunto de ferramentas para a análise funcional de comunidades microbianas baseadas nas súas secuencias metaxenómicas, baseándose en xenomas illados de referencia incluídos no sistema Integrated Microbial Genomes (IMG) e o proxecto Genomic Encyclopedia of Bacteria and Archaea (GEBA).[49]
Unha das primeiras ferramentas autónomas para analizar datos de escopeta metaxenómicos de alto rendemento foi MEGAN (MEta Genome ANalyzer).[36][41] Unha primeira versión do programa foi utilizada en 2005 para analizar o contexto metaxenómico de secuencias de ADN obtidas de ósos de mamut.[17] Baseándose nunha comparación entre BLAST e unha base de datos de referencia, esta ferramenta realiza agrupamentos tanto taxonómicos coma funcionais, ao situar estas lecturas sobre os nodos da taxonomía do NCBI usando un simple algoritmo de antepasado común máis baixo (Lower common ancestor, LCA) ou nos nodos das clasificacións de SEED ou KEGG, respectivamente. [50]
Co advimento de instrumentos de secuenciación rápida e barata, o crecemento das bases de datos de secuencias de ADN é agora exponencial (por exemplo, a base de datos GenBank do NCBI [51]). Cómpren ferramentas máis rápidas e eficientes para manter o ritmo coa secuenciación de alto rendemento, porque as estratexias baseadas en BLAST como MG-RAST ou MEGAN funcionan lentamente á hora de anotar grandes mostras (por exemplo, varias horas para procesar unha base de datos/mostra de tamaño pequeno/medio [52]). Así, recentemente apareceron os clasificadores ultrarrápidos, grazas a servidores poderosos e máis económicos. Estas ferramentas poden realizar a anotación taxonómica a unha velocidade extremadamente alta, por exemplo CLARK [53] (de acordo cos autores de CLARK, pode clasificar con exactitude "32 millóns de lecturas curtas metaxenómicas por minuto"). A esa velocidade, unha base de datos/mostra moi grande de mil millóns de lecturas curtas pode ser procesadas nuns 30 minutos.
Coa dispoñibilidade cada vez maior de mostras que conteñen ADN antigo e debido á incerteza asociada coa natureza desas mostras (danos no ADN antigo), fíxose dispoñible FALCON,[54] unha ferramenta rápida que pode producir estimacións de semellanza conservadoras. Segundo os autores de FALCON, este pode usar limiares relaxados e editar ou corixir distancias sen afectar á memoria e o rendemento de velocidade.
Metaxenómica comparativa editar
As análises comparativas entre metaxenomas poden axudar a comprender as funcións de comunidades microbianas complexas e o seu papel na saúde dos hóspedes.[55] As comparación por pares ou múltiples entre metaxenomas poden realizarse a nivel de composición da secuencia (comparando o contido GC ou o tamaño do xenoma), da diversidade taxonómica ou do complemento funcional. As comparacións da estrutura da poboación e a diversidade filoxenética poden realizarse baseándose no xene do ARNr 16S e outros xenes marcadores filoxenéticos ou, en caso de que se trate de comunidade con baixa diversidade, por reconstrución do xenoma a partir dos conxuntos de datos metaxenómicos.[56] As comparacións funcionais entre metaxenomas poden realizarse comparando secuencias con bases de datos de referencia como COG ou KEGG e tabulando a abundancia por categoría e avaliando calquera diferenza pola súa significatividade estatística.[50] Esta estratexia centrada nos xenes pon a énfase no complemento funcional da comunidade no seu conxunto en vez de nos grupos taxonómicos e mostra que os complementos funcionais son análogos baixo condicións ambientais similares.[56] En consecuencia, os metadatos sobre o contexto ambiental das mostras metaxenómicas son especialmente importante en análises comparativas, xa que proporcionan aos investigadores a capacidade de estudaren o efecto do hábitat sobre a estrutura e función da comunidade.[25]
Ademais, varios estudos utilizaron os padróns de uso de oligonucleótidos para identificar as diferenzas en diversas comunidades microbianas. Son exemplos desas tecnoloxías as enfocadas á abundacia relativa de dinucleótidos de Willner et al.[57] e o método HabiSign de Ghosh et al.[58] Este último estudo tamén indicou que as diferenzas nos padróns de uso de tetranucleótidos poden utilizarse para identificar xenes (ou lecturas metaxenómicas) orixinados en hábitats específicos. Ademais, algúns métodos como TriageTools[59] ou Compareads[60] detectan lecturas similares entre dous conxuntos de lecturas. A medida de similitude que aplican ás lecturas está baseada na cantidade de palabras idénticas de lonxitude k compartidas por pares de lecturas.
Un obxectivo central na metaxenómica comparativa é identificar grupo(s) microbianos que son os responsables de darlle características específicas a un ambiente determinado. Porén, debido a problemas nas tecnoloxías de secuenciación hai que ter en conta os artefactos como en metagenomeSeq.[28] Outros caracterizaron interaccións intermicrobianas entre os grupos microbianos residentes. Kuntal el al. desenvolveron unha aplicación de análise metaxenómica comparativa baseada en GUI chamada Community-Analyzer, [61] que aplica un algoritmo de deseño de gráficos baseado na correlación que non só facilita unha rápida visualización das diferenzas nas comunidades microbianas analizadas (en canto á súa composición taxonómica), senón que tamén proporciona coñecementos sobre as interaccións intermicrobianas inherentes que ocorren nelas. Especialmente, este algoritmo de deseño tamén permite agrupar os metaxenomas baseados nos padróns de interacción intermicrobiana probables en vez de comparar simplemente os valores de abundancia de varios grupos taxonómicos. Ademais, a feramenta aplica varias funcionalidades interactivas baseadas en GUI que permiten aos usuarios realizar análises estándar comparativas sobre microbiomas.
Análise de datos editar
Metabolismo da comunidade editar
En moitas comunidades bacterianas, naturais ou preparadas por enxeñaría (como os biorreactores), hai unha división do traballo significativa no metabolismo (sintrofia), durante a cal os produtos residuais dalgúns organismos son metabolitos para outras.[62] Nun sistema como ese, a estabilidade funcional do biorreactor metanóxeno require a presenza de varias especies sintróficas (Syntrophobacterales e Synergistia) que traballan xuntas para converter os recursos en bruto en residuos completamente metabolizados (metano). [63] Utilizando estudos de xenes comparativos e experimentos de expresión con micromatrices ou proteómica, os investigadores poden encontrar o sentido a unha rede metabólica que vai alén das fronteiras da especie. Tales estudos requiren un coñecemento detallado sobre que versións de que proteínas están codificadas por cada especie e mesmo por cada cepa. Xa que logo, a información xenómica da comunidade é outra ferramenta fundamental (coa metabolómica e a proteómica) para investigar como os metabolitos son transferidos e transformados pola comunidade.[64]
Metatranscritómica editar
- Artigos principais: Transcritoma, Tecnoloxía transcritómicas e Metatranscritómica.
A mataxenómica permite que os investigadores accedan á diversidade funcional e metabólica das comunidades microbianas, pero non pode mostrar cales destes procesos son activos.[56] A extracción e análise de ARNm metaxenómico (o metatranscritoma) proporciona información sobre os perfís de regulación e expresión xénica de comunidades complexas. Debido ás dificultades técnicas (a curta vida media do ARNm, por exemplo) na recollida de ARN ambiental ata agora téñense feito relativamente poucos estudos metatranscritómicos in situ de comunidades microbianas.[56] Aínda que os estudos metatranscritómicos orixinalmente estaban limitados á tecnoloxía das micromatrices, despois utilizaron tecnoloxías transcritómicas para medir a expresión de xenomas completos e a cuantificación dunha comunidade microbiana,[56] empregada primeiro na análise da oxidación do amoníaco no solo.[65] [66]
Virus editar
- Artigo principal: Metaxenómica viral.
A secuenciación metaxenómica é especialmente útil no estudo de comunidades virais. Dado que os virus carecen dun marcador filoxenético universal compartido (como o ARNr 16S en bacterias e arqueas e o ARNr 18S en eucariotas), o único xeito de acceder á diversidade xenética da comunidade viral a partir dunha mostra ambiental é por medio da metaxenómica. Os metaxenomas virais (tamén chamados viromas) deberían así proporcionar cada vez máis información sobre a diversidade e evolución viral.[66][67][68][69][70] Por exemplo, unha tubaxe metaxenómica chamada Giant Virus Finder mostrou a primeira proba da existencia de virus xigantes nun deserto salino[71] e en vales antárticos secos.[72]
Aplicacións editar
A metaxenómica ten o potencial de aumentar o noso coñecemento en moitos campos. Pode aplicarse para resolver retos prácticos en medicina, enxeñaría, agricultura, sostibilidade e ecoloxía.[29][73]
Agricultura editar
O solo, no cal crecen as plantas, está habitado por comunidades microbianas, e un só gramo de solo contén unhas 109-1010 células microbianas, as cales conteñen aproximadamente unha xigabase de información de secuencia.[74][75] As comunidaes microbianas que viven no solo son algunhas das máis complexas coñecidas pola ciencia e son aínda pouco comprendidas malia a súa importancia económica.[76] Os consorcios microbianos realizan unha ampla variedade de servizos aos ecosistemas necesarios para o crecemento das plantas, incluíndo a fixación do nitróxeno atmosférico, a reciclaxe de nutrientes, a supresión de enfermidades e secuestran o ferro e outros metais.[77] As estratexias da metaxenómica funcional están utilizándose para explorar as interaccións entre as plantas e os microbios por medio dun estudo independente do cultivo destas comunidades microbianas.[78][79] As estratexias da metaxenómica, ao permitiren coñecer no papel de membros da comunidade raros ou previamente non cultivados na reciclaxe de nutrientes e a promoción do crecemento das plantas, poden contribuír a mellorar a detección de enfermidades en plantas de cultivo e no gando e a adaptación de prácticas agrícolas axeitadas, que melloran a saúde ao aproveitaren as relacións entre microbios e plantas.[29]
Biocombustible editar
- Artigo principal: Biofuel.

Os biocombustibles son combustibles derivados a partir da conversión de biomasa, como na conversión da celulosa contida nos talos de millo, Panicum virgatum, e outras biomasas en etanol celulósico.[29] Este proceso depende dos consorcios (asociacións) microbianos que transforman a celulosa en azucres, que seguidamente son fermentados orixinando etanol. Os microbios tamén producen diversas fontes de bioenerxía, como metano e hidróxeno.[29]
A deconstrución a escala industrial eficiente da biomasa require novos encimas cunha maior produtividade e menor custo.[26] As estratexias metaxenómicas para analizar comunidades microbianas complexas permiten facer un cribado dirixido a unha diana encimática con aplicacións industriais na produción de biocombustibles, como as glicósido hidrolases.[80] Ademais, o coñecemento de como funcionan estas comunidades microbianas é necesario para controlalas e a metaxenómica é unha ferramenta clave para a súa comprensión. As aproximacións metaxenómicas permiten unha análise comparativa entre os sistemas microbianos converxentes como os dos fermentadores de biogás[81] ou dos insectos herbívoros, como os dos xardíns de fungos das formigas cortadoras de follas (dos xéneros Atta e Acromyrmex).[82]
Biotecnoloxía editar
As comunidades microbianas producen un amplo conxunto de compostos químicos bioloxicamente activos que utilizan para competir e comunicarse.[77] Moitos dos fármacos que se usan hoxe foron orixinalmente descubertos en microbios; os progresos recentes na extracción da riqueza de recursos xenéticos dos microbios non cultivables levou ao descubrimento de novos xenes, encimas e produtos naturais.[56][56] [83] As aplicacións da metaxenómica permitiron o desenvolvemento de produtos químicos básicos, produtos complexos de química fina, produtos agroquímicos e fármacos, nos que o beneficio da síntese quiral catalizada por encimas é cada vez máis recoñecida.[84]
Utilízanse dous tipos de análises na bioprospección de datos metaxenómicos: cribado dirixido á función para un trazo expresado, e cribado dirixido á secuencia para secuencias de ADN de interese.[85] A análise dirixida á función trata de identificar clons que expresan un trazo desexado ou actividade útil, seguidos da caracterización bioquímica e análise de secuencia. Esta estratexia está limitada pola dispoñibilidade dun cribado axeitado e a necesidade de que o trazo desexado se exprese na célula hóspede. Ademais, a baixa taxa de descubrimento (menor de 1 por cada 1000 clons cribados) e a súa natureza laboriosa limitan tamén esta estratexia.[86] En contraste, a análise dirixida á secuencia usa secuencias de ADN conservadas para o deseño de cebadores para clons de cribado para a secuencia de interese.[85] En comparación coas estratexias baseadas na clonación, usar unha estratexia baseada só na secuencia reduce ademais a cantidade de traballo que se precisa. A aplicación de secuenciación masivamente paralela tamén incrementa grandemente a cantidade de datos de secuencia xerados, que require tubaxes de análise informática de alto rendemento.[86] A estratexia dirixida á secuencia para o cribado está limitada pola amplitude e exactitude das funcións xénicas presentes en secuencias de bases de datos públicas. Na práctica, os experimentos poden utilizar unha combinación de estratexias tanto funcionais coma centrados na secuencia baseadas na función de interese, a complexidade da mostra que vai ser cribada e outros factores.[86][87] Un exemplo de éxito obtido usando a metaxenómica como biotecnoloxía para o descubrimento de fármacos pode ilustrarse cos antibióticos malacidina.[88]
Ecoloxía editar
A metaxenómica pode proporcionar unha valiosa perspectiva para estudar a ecoloxía funcional de comunidades ambientais.[89] A análise metaxenómica dos consorcios bacterianos atopados nas feces de leóns mariños australianos suxiren que as feces de leóns mariños ricas en nutrientes poden ser unha importante fonte de nutrientes para os ecosistemas costeiros. Isto débese a que as bacterias que son expulsadas simultaneamente coas defecacións dedícanse a degradar os nutrientes presentes nas feces a unha forma biodispoñible que pode ser captada na cadea alimenticia.[90]
A secuenciación de ADN pode tamén utilizarse máis amplamente para identificar as especies presentes nun corpo de auga,[91] residuos filtrados do aire ou mostras de lixo. Isto pode establecer o rango de especies invasoras e especies en perigo e monitorizar poboacións estacionais.
Remediación ambiental editar
- Artigo principal: Biorremediación.
A metaxenómica pode mellorar as estratexias para monitorizar o impacto de contaminantes nos ecosistemas e para limpar ambientes contaminados. O aumento da comprensión de como as comunidades microbianas tratan os contaminantes mellora as valoracións do potencial que teñen os sitios contaminados para recuperarse da polución e incrementa as posibilidades de que teña éxito o bioaumento ou os ensaios de bioestimulación.[92]
Caracterización de microbios da flora intestinal editar
As comunidades microbianas desempeñan un papel clave na preservación da saúde humana, pero a súa composición e o mecanismo polo cal o fan segue sen coñecerse.[93] A secuenciación metaxenómica está sendo utilizada para caracterizar as comunidades microbianas en de 15 a 18 sitios en polo menos 250 individuos. Isto forma parte do Proxecto Microbioma Humano cuxos obxectivos primarios son determinar se hai un microbioma humano básico, para comprender os cambios no microbioma humano que poden ser correlacionados coa saúde humana e para desenvolver novas tecnoloxías e ferramentas bioinformáticas para conseguir eses obxectivos.[94]
Outros estudos médicos como parte do proxecto MetaHit (Metaxenómica do Tracto Intestinal Humano) examinaron 124 individuos de Dinamarca e España que eran pacientes de colon irritable, ou con sobrepeso ou con boa saúde. O estudo trataba de categorizar a profundidade e diversidade filoxenética das bacterias gastrointestinais. Usando datos de secuencias Illumina GA e SOAPdenovo, unha ferramenta baseada en gráficos de Bruijn deseñada especificamente para a ensamblaxe de lecturas curtas, puidéronse xerar 6,58 millóns de cóntigos de máis de 500 pares de bases para unha lonxitude de cóntigo total de 10,3 Gb e unha lonxitude N50 de 2,2 kb.
O estudo demostrou que dúas divisións bacterianas, Bacteroidetes e Firmicutes, constitúen o 90% das categorías filoxenéticas coñecidas que dominan a flora intestinal. Usando as frecuencias xénicas relativas que se atopan na flora intestinal estes investigadores identificaron 1244 agrupacións metaxenómicas que son esencialmente importantes para a saúde do tracto intestinal. Estas agrupacións realizan dous tipos de funcións: labores de mantemento (housekeeping) e outros específicos do intestino. Os agrupamentos de xenes de mantemento son necesarios en todas as bacterias e adoitan ser elementos importantes nas principais vías metabólicas, incluíndo o metabolismo central do carbono e síntese de aminoácidos. As funcións específicas do intestino inclúen a adhesión a proteínas do hóspede e a recollida de azucres de glicolípidos globoseries (glicoesfingolípidos que conteñen un enlace de tipo galabiosa). Os pacientes con síndrome de colon irritable presentan un 25% menos de xenes bacterianos e menor diversidade bacteriana que os individuos que non sofren esa doenza, o que indica que os cambios na diversidade do bioma do intestino dos pacientes poden asociarse con esta condición.
Aínda que estes estudos salientan algunhas aplicacións médicas potencialmente valiosas, só do 31 ao 48,8% das lecturas puideron ser aliñadas a 194 xenomas públicos de bacterias intestinais humanas e do 7,6 a 21,2% a xenomas bacterianos dispoñibles en GenBank, o cal indica que aínda cómpre facer moitas investigacións para obter novos xenomas bacterianos.[95]
Diagnóstico de enfermidades infecciosas editar
A diferenciación entre enfermidades infecciosas e non infecciosas e a identificación da etoloxía subxacente da infección, pode ser un reto importante. Por exemplo, máis da metade dos casos de encefalite quedan sen diagnosticar, malia as amplas probas que se realizan usando métodos clínicos de laboratorio de vangarda. A secuenciación metaxenómica é moi prometedora como método rápido e sensible para diagnosticar a infección comparando o material xenético atopado nunha mostra do paciente cunha base de datos de miles de bacterias, virus e outros patóxenos.
Notas editar
- ↑ 1,0 1,1 Hugenholz, P; Goebel BM; Pace NR (1 September 1998). "Impact of Culture-Independent Studies on the Emerging Phylogenetic View of Bacterial Diversity". J. Bacteriol. 180 (18): 4765–74. PMC 107498. PMID 9733676.
- ↑ Marco, D, ed. (2011). Metagenomics: Current Innovations and Future Trends. Caister Academic Press. ISBN 978-1-904455-87-5.
- ↑ Eisen, JA (2007). "Environmental Shotgun Sequencing: Its Potential and Challenges for Studying the Hidden World of Microbes". PLoS Biology 5 (3): e82. PMC 1821061. PMID 17355177. doi:10.1371/journal.pbio.0050082.
- ↑ Handelsman, J.; Rondon, M. R.; Brady, S. F.; Clardy, J.; Goodman, R. M. (1998). "Molecular biological access to the chemistry of unknown soil microbes: A new frontier for natural products". Chemistry & Biology 5 (10): R245–R249. PMID 9818143. doi:10.1016/S1074-5521(98)90108-9..
- ↑ Chen, K.; Pachter, L. (2005). "Bioinformatics for Whole-Genome Shotgun Sequencing of Microbial Communities". PLoS Computational Biology 1 (2): 106–12. Bibcode:2005PLSCB...1...24C. PMC 1185649. PMID 16110337. doi:10.1371/journal.pcbi.0010024.
- ↑ Lane, DJ; Pace B; Olsen GJ; Stahl DA; Sogin ML; Pace NR (1985). "Rapid determination of 16S ribosomal RNA sequences for phylogenetic analyses". Proceedings of the National Academy of Sciences 82 (20): 6955–9. Bibcode:1985PNAS...82.6955L. PMC 391288. PMID 2413450. doi:10.1073/pnas.82.20.6955.
- ↑ Pace, NR; DA Stahl; DJ Lane; GJ Olsen (1985). "Analyzing natural microbial populations by rRNA sequences". ASM News 51: 4–12. Arquivado dende o orixinal o 04 de abril de 2012. Consultado o 13 de decembro de 2019.
- ↑ Pace, NR; Delong, EF; Pace, NR (1991). "Analysis of a marine picoplankton community by 16S rRNA gene cloning and sequencing". Journal of Bacteriology 173 (14): 4371–4378. PMC 208098. PMID 2066334. doi:10.1128/jb.173.14.4371-4378.1991.
- ↑ Healy, FG; RM Ray; HC Aldrich; AC Wilkie; LO Ingram; KT Shanmugam (1995). "Direct isolation of functional genes encoding cellulases from the microbial consortia in a thermophilic, anaerobic digester maintained on lignocellulose". Appl. Microbiol. Biotechnol. 43 (4): 667–74. PMID 7546604. doi:10.1007/BF00164771.
- ↑ Stein, JL; TL Marsh; KY Wu; H Shizuya; EF DeLong (1996). "Characterization of uncultivated prokaryotes: isolation and analysis of a 40-kilobase-pair genome fragment from a planktonic marine archaeon". Journal of Bacteriology 178 (3): 591–599. PMC 177699. PMID 8550487. doi:10.1128/jb.178.3.591-599.1996.
- ↑ Breitbart, M; Salamon P; Andresen B; Mahaffy JM; Segall AM; Mead D; Azam F; Rohwer F (2002). "Genomic analysis of uncultured marine viral communities". Proceedings of the National Academy of Sciences of the United States of America 99 (22): 14250–14255. Bibcode:2002PNAS...9914250B. PMC 137870. PMID 12384570. doi:10.1073/pnas.202488399.
- ↑ 12,0 12,1 Tyson, GW; Chapman J; Hugenholtz P; Allen EE; Ram RJ; Richardson PM; Solovyev VV; Rubin EM; Rokhsar DS; Banfield JF (2004). "Insights into community structure and metabolism by reconstruction of microbial genomes from the environment". Nature 428 (6978): 37–43. Bibcode:2004Natur.428...37T. PMID 14961025. doi:10.1038/nature02340.
- ↑ Hugenholz, P (2002). "Exploring prokaryotic diversity in the genomic era". Genome Biology 3 (2): 1–8. PMC 139013. PMID 11864374. doi:10.1186/gb-2002-3-2-reviews0003.
- ↑ Thomas, T.; Gilbert, J.; Meyer, F. (2012). "Metagenomics - a guide from sampling to data analysis". Microbial Informatics and Experimentation 2 (1): 3. PMC 3351745. PMID 22587947. doi:10.1186/2042-5783-2-3.
- ↑ Venter, JC; Remington K; Heidelberg JF; Halpern AL; Rusch D; Eisen JA; Wu D; Paulsen I; Nelson KE; Nelson W; Fouts DE; Levy S; Knap AH; Lomas MW; Nealson K; White O; Peterson J; Hoffman J; Parsons R; Baden-Tillson H; Pfannkoch C; Rogers Y; Smith HO (2004). "Environmental Genome Shotgun Sequencing of the Sargasso Sea". Science 304 (5667): 66–74. Bibcode:2004Sci...304...66V. PMID 15001713. doi:10.1126/science.1093857.
- ↑ Yooseph, Shibu; Kenneth H. Nealson; Douglas B. Rusch; John P. McCrow; Christopher L. Dupont; Maria Kim; Justin Johnson; Robert Montgomery; Steve Ferriera; Karen Beeson; Shannon J. Williamson; Andrey Tovchigrechko; Andrew E. Allen; Lisa A. Zeigler; Granger Sutton; Eric Eisenstadt; Yu-Hui Rogers; Robert Friedman; Marvin Frazier; J. Craig Venter (4 November 2010). "Genomic and functional adaptation in surface ocean planktonic prokaryotes". Nature 468 (7320): 60–66. Bibcode:2010Natur.468...60Y. ISSN 0028-0836. PMID 21048761. doi:10.1038/nature09530.
- ↑ 17,0 17,1 17,2 Poinar, HN; Schwarz, C; Qi, J; Shapiro, B; Macphee, RD; Buigues, B; Tikhonov, A; Huson, D; Tomsho, LP; Auch, A; Rampp, M; Miller, W; Schuster, SC (2006). "Metagenomics to Paleogenomics: Large-Scale Sequencing of Mammoth DNA". Science 311 (5759): 392–394. Bibcode:2006Sci...311..392P. PMID 16368896. doi:10.1126/science.1123360.
- ↑ Edwards, RA; Rodriguez-Brito B; Wegley L; Haynes M; Breitbart M; Peterson DM; Saar MO; Alexander S; Alexander EC; Rohwer F (2006). "Using pyrosequencing to shed light on deep mine microbial ecology". BMC Genomics 7: 57. PMC 1483832. PMID 16549033. doi:10.1186/1471-2164-7-57.
- ↑ Beja, O.; Suzuki, MT; Koonin, EV; Aravind, L; Hadd, A; Nguyen, LP; Villacorta, R; Amjadi, M; Garrigues, C (2000). "Construction and analysis of bacterial artificial chromosome libraries from a marine microbial assemblage". Environmental Microbiology 2 (5): 516–29. PMID 11233160. doi:10.1046/j.1462-2920.2000.00133.x.
- ↑ 20,0 20,1 Nicola, Segata; Daniela Boernigen; Timothy L Tickle; Xochitl C Morgan; Wendy S Garrett; Curtis Huttenhower (2013). "Computational meta'omics for microbial community studies". Molecular Systems Biology 9 (666): 666. PMC 4039370. PMID 23670539. doi:10.1038/msb.2013.22.
- ↑ Watson, Mick; Roehe, Rainer; Walker, Alan W.; Dewhurst, Richard J.; Snelling, Timothy J.; Ivan Liachko; Langford, Kyle W.; Press, Maximilian O.; Wiser, Andrew H. (28 February 2018). "Assembly of 913 microbial genomes from metagenomic sequencing of the cow rumen". Nature Communications (en inglés) 9 (1): 870. Bibcode:2018NatCo...9..870S. ISSN 2041-1723. PMC 5830445. PMID 29491419. doi:10.1038/s41467-018-03317-6.
- ↑ Rodrigue, S. B.; Materna, A. C.; Timberlake, S. C.; Blackburn, M. C.; Malmstrom, R. R.; Alm, E. J.; Chisholm, S. W. (2010). Gilbert, Jack Anthony, ed. "Unlocking Short Read Sequencing for Metagenomics". PLoS ONE 5 (7): e11840. Bibcode:2010PLoSO...511840R. PMC 2911387. PMID 20676378. doi:10.1371/journal.pone.0011840.
- ↑ Schuster, S. C. (2007). "Next-generation sequencing transforms today's biology". Nature Methods 5 (1): 16–18. PMID 18165802. doi:10.1038/nmeth1156.
- ↑ 24,0 24,1 "Metagenomics versus Moore's law". Nature Methods 6 (9): 623. 2009. doi:10.1038/nmeth0909-623.
- ↑ 25,0 25,1 25,2 25,3 25,4 25,5 Wooley, J. C.; Godzik, A.; Friedberg, I. (2010). Bourne, Philip E., ed. "A Primer on Metagenomics". PLoS Computational Biology 6 (2): e1000667. Bibcode:2010PLSCB...6E0667W. PMC 2829047. PMID 20195499. doi:10.1371/journal.pcbi.1000667.
- ↑ 26,0 26,1 Hess, Matthias; Alexander Sczyrba; Rob Egan; Tae-Wan Kim; Harshal Chokhawala; Gary Schroth; Shujun Luo; Douglas S Clark; Feng Chen; Tao Zhang; Roderick I Mackie; Len A Pennacchio; Susannah G Tringe; Axel Visel; Tanja Woyke; Zhong Wang; Edward M Rubin (28 January 2011). "Metagenomic discovery of biomass-degrading genes and genomes from cow rumen". Science 331 (6016): 463–467. Bibcode:2011Sci...331..463H. ISSN 1095-9203. PMID 21273488. doi:10.1126/science.1200387.
- ↑ Qin, Junjie; Ruiqiang Li; Jeroen Raes; Manimozhiyan Arumugam; Kristoffer Solvsten Burgdorf; Chaysavanh Manichanh; Trine Nielsen; Nicolas Pons; Florence Levenez; Takuji Yamada; Daniel R. Mende; Junhua Li; Junming Xu; Shaochuan Li; Dongfang Li; Jianjun Cao; Bo Wang; Huiqing Liang; Huisong Zheng; Yinlong Xie; Julien Tap; Patricia Lepage; Marcelo Bertalan; Jean-Michel Batto; Torben Hansen; Denis Le Paslier; Allan Linneberg; H. Bjorn Nielsen; Eric Pelletier; Pierre Renault; Thomas Sicheritz-Ponten; Keith Turner; Hongmei Zhu; Chang Yu; Shengting Li; Min Jian; Yan Zhou; Yingrui Li; Xiuqing Zhang; Songgang Li; Nan Qin; Huanming Yang; Jian Wang; Soren Brunak; Joel Dore; Francisco Guarner; Karsten Kristiansen; Oluf Pedersen; Julian Parkhill; Jean Weissenbach; Peer Bork; S. Dusko Ehrlich; Jun Wang (4 March 2010). "A human gut microbial gene catalogue established by metagenomic sequencing". Nature 464 (7285): 59–65. Bibcode:2010Natur.464...59.. ISSN 0028-0836. PMC 3779803. PMID 20203603. doi:10.1038/nature08821.
- ↑ 28,0 28,1 Paulson, Joseph; O Colin Stine; Hector Corrada Bravo; Mihai Pop (2013). "Differential abundance analysis for microbial marker-gene surveys". Nature Methods 10 (12): 1200–1202. PMC 4010126. PMID 24076764. doi:10.1038/nmeth.2658.
- ↑ 29,0 29,1 29,2 29,3 29,4 29,5 29,6 Committee on Metagenomics: Challenges and Functional Applications, National Research Council (2007). The New Science of Metagenomics: Revealing the Secrets of Our Microbial Planet. Washington, D.C.: The National Academies Press. ISBN 978-0-309-10676-4. PMID 21678629. doi:10.17226/11902.
- ↑ Oulas, A; Pavloudi, C; Polymenakou, P; Pavlopoulos, GA; Papanikolaou, N; Kotoulas, G; Arvanitidis, C; Iliopoulos, I (2015). "Metagenomics: tools and insights for analyzing next-generation sequencing data derived from biodiversity studies". Bioinformatics and Biology Insights 9: 75–88. PMC 4426941. PMID 25983555. doi:10.4137/BBI.S12462.
- ↑ Mende, Daniel R.; Alison S. Waller; Shinichi Sunagawa; Aino I. Järvelin; Michelle M. Chan; Manimozhiyan Arumugam; Jeroen Raes; Peer Bork (23 February 2012). "Assessment of Metagenomic Assembly Using Simulated Next Generation Sequencing Data". PLoS ONE 7 (2): e31386. Bibcode:2012PLoSO...731386M. ISSN 1932-6203. PMC 3285633. PMID 22384016. doi:10.1371/journal.pone.0031386.
- ↑ Balzer, S.; Malde, K.; Grohme, M. A.; Jonassen, I. (2013). "Filtering duplicate reads from 454 pyrosequencing data". Bioinformatics 29 (7): 830–836. PMC 3605598. PMID 23376350. doi:10.1093/bioinformatics/btt047.
- ↑ Mohammed, MH; Sudha Chadaram; Dinakar Komanduri; Tarini Shankar Ghosh; Sharmila S Mande (2011). "Eu-Detect: an algorithm for detecting eukaryotic sequences in metagenomic data sets". Journal of Biosciences 36 (4): 709–717. PMID 21857117. doi:10.1007/s12038-011-9105-2.
- ↑ R, Schmeider; R Edwards (2011). "Fast identification and removal of sequence contamination from genomic and metagenomic datasets". PLoS ONE 6 (3): e17288. Bibcode:2011PLoSO...617288S. PMC 3052304. PMID 21408061. doi:10.1371/journal.pone.0017288.
- ↑ 35,0 35,1 35,2 35,3 35,4 Kunin, V.; Copeland, A.; Lapidus, A.; Mavromatis, K.; Hugenholtz, P. (2008). "A Bioinformatician's Guide to Metagenomics". Microbiology and Molecular Biology Reviews 72 (4): 557–578, Table 578 Contents. PMC 2593568. PMID 19052320. doi:10.1128/MMBR.00009-08.
- ↑ 36,0 36,1 36,2 Huson, Daniel H; S. Mitra; N. Weber; H. Ruscheweyh; Stephan C. Schuster (June 2011). "Integrative analysis of environmental sequences using MEGAN4". Genome Research 21 (9): 1552–1560. PMC 3166839. PMID 21690186. doi:10.1101/gr.120618.111.
- ↑ Burton, J. N.; Liachko, I.; Dunham, M. J.; Shendure, J. (2014). "Species-Level Deconvolution of Metagenome Assemblies with Hi-C-Based Contact Probability Maps". G3: Genes, Genomes, Genetics 4 (7): 1339–1346. PMC 4455782. PMID 24855317. doi:10.1534/g3.114.011825.
- ↑ Zhu, Wenhan; Lomsadze Alex; Borodovsky Mark (2010). "Ab initio gene identification in metagenomic sequences". Nucleic Acids Research 38 (12): e132. PMC 2896542. PMID 20403810. doi:10.1093/nar/gkq275.
- ↑ Hug, Laura A.; Baker, Brett J.; Anantharaman, Karthik; Brown, Christopher T.; Probst, Alexander J.; Castelle, Cindy J.; Butterfield, Cristina N.; Hernsdorf, Alex W.; Amano, Yuki; Ise, Kotaro; Suzuki, Yohey; Dudek, Natasha; Relman, David A.; Finstad, Kari M.; Amundson, Ronald; Thomas, Brian C.; Banfield, Jillian F. (11 April 2016). "A new view of the tree of life". Nature Microbiology 1 (5): 16048. PMID 27572647. doi:10.1038/nmicrobiol.2016.48.
- ↑ Konopka, A. (2009). "What is microbial community ecology?". The ISME Journal 3 (11): 1223–1230. PMID 19657372. doi:10.1038/ismej.2009.88.
- ↑ 41,0 41,1 41,2 Huson, Daniel H; A. Auch; Ji Qi; Stephan C Schuster (January 2007). "MEGAN Analysis of Metagenomic Data". Genome Research 17 (3): 377–386. PMC 1800929. PMID 17255551. doi:10.1101/gr.5969107.
- ↑ Nicola, Segata; Levi Waldron; Annalisa Ballarini; Vagheesh Narasimhan; Olivier Jousson; Curtis Huttenhower (2012). "Metagenomic microbial community profiling using unique clade-specific marker genes". Nature Methods 9 (8): 811–814. PMC 3443552. PMID 22688413. doi:10.1038/nmeth.2066.
- ↑ Sunagawa, Shinichi; et al. (2013). "Metagenomic species profiling using universal phylogenetic marker genes.". Nature Methods 10 (12): 1196–1199. PMID 24141494. doi:10.1038/nmeth.2693.
- ↑ 44,0 44,1 Milanese, Alessio; et al. (2019). "Microbial abundance, activity and population genomic profiling with mOTUs2". Nature Communications 10 (1): 1014. Bibcode:2019NatCo..10.1014M. PMC 6399450. PMID 30833550. doi:10.1038/s41467-019-08844-4.
- ↑ Liu, Bo; et al. (2011). "Accurate and fast estimation of taxonomic profiles from metagenomic shotgun sequences". BMC Genomics 12: S4. PMC 3194235. PMID 21989143. doi:10.1186/1471-2164-12-S2-S4.
- ↑ Dadi, Temesgen Hailemariam; Renard, Bernhard Y.; Wieler, Lothar H.; Semmler, Torsten; Reinert, Knut (2017). "SLIMM: species level identification of microorganisms from metagenomes". PeerJ 5: e3138. ISSN 2167-8359. PMC 5372838. PMID 28367376. doi:10.7717/peerj.3138.
- ↑ Pagani, Ioanna; Konstantinos Liolios; Jakob Jansson; I-Min A Chen; Tatyana Smirnova; Bahador Nosrat; Victor M Markowitz; Nikos C Kyrpides (1 December 2011). "The Genomes OnLine Database (GOLD) v.4: status of genomic and metagenomic projects and their associated metadata". Nucleic Acids Research 40 (1): D571–9. ISSN 1362-4962. PMC 3245063. PMID 22135293. doi:10.1093/nar/gkr1100.
- ↑ Meyer, F; Paarmann D; D'Souza M; Olson R; Glass EM; Kubal M; Paczian T; Rodriguez A; Stevens R; Wilke A; Wilkening J; Edwards RA (2008). "The metagenomics RAST server – a public resource for the automatic phylogenetic and functional analysis of metagenomes". BMC Bioinformatics 9: 0. PMC 2563014. PMID 18803844. doi:10.1186/1471-2105-9-386.
- ↑ Markowitz, V. M.; Chen, I. -M. A.; Chu, K.; Szeto, E.; Palaniappan, K.; Grechkin, Y.; Ratner, A.; Jacob, B.; Pati, A.; Huntemann, M.; Liolios, K.; Pagani, I.; Anderson, I.; Mavromatis, K.; Ivanova, N. N.; Kyrpides, N. C. (2011). "IMG/M: The integrated metagenome data management and comparative analysis system". Nucleic Acids Research 40 (Database issue): D123–D129. PMC 3245048. PMID 22086953. doi:10.1093/nar/gkr975.
- ↑ 50,0 50,1 Mitra, Suparna; Paul Rupek; Daniel C Richter; Tim Urich; Jack A Gilbert; Folker Meyer; Andreas Wilke; Daniel H Huson (2011). "Functional analysis of metagenomes and metatranscriptomes using SEED and KEGG". BMC Bioinformatics. 12 Suppl 1: S21. ISSN 1471-2105. PMC 3044276. PMID 21342551. doi:10.1186/1471-2105-12-S1-S21.
- ↑ Benson, Dennis; Mark Cavanaugh; Karen Clark; et al. (2013). "Genbank". Nucleic Acids Research 41 (Database issue): D36–D42. PMC 3531190. PMID 23193287. doi:10.1093/nar/gks1195.
- ↑ Bazinet, Adam; Michael Cummings (2012). "A comparative evaluation of sequence classification programs". BMC Bioinformatics 13: 92. PMC 3428669. PMID 22574964. doi:10.1186/1471-2105-13-92.
- ↑ Ounit, Rachid; Steve Wanamaker; Timothy Close; Stefano Lonardi (2015). "CLARK: fast and accurate classification of metagenomic and genomic sequences using discriminative k-mers". BMC Genomics 16: 236. PMC 4428112. PMID 25879410. doi:10.1186/s12864-015-1419-2.
- ↑ Pratas D; Pinho AJ; Silva RM; Rodrigues JMOS; Hosseini M; Caetano T; Ferreira PJSG (February 2018). "FALCON: a method to infer metagenomic composition of ancient DNA". bioRxiv 267179. [1]
- ↑ Kurokawa, Ken; Takehiko Itoh; Tomomi Kuwahara; Kenshiro Oshima; Hidehiro Toh; Atsushi Toyoda; Hideto Takami; Hidetoshi Morita; Vineet K. Sharma; Tulika P. Srivastava; Todd D. Taylor; Hideki Noguchi; Hiroshi Mori; Yoshitoshi Ogura; Dusko S. Ehrlich; Kikuji Itoh; Toshihisa Takagi; Yoshiyuki Sakaki; Tetsuya Hayashi; Masahira Hattori (1 January 2007). "Comparative Metagenomics Revealed Commonly Enriched Gene Sets in Human Gut Microbiomes". DNA Research 14 (4): 169–181. PMC 2533590. PMID 17916580. doi:10.1093/dnares/dsm018. Consultado o 18 December 2011.
- ↑ 56,0 56,1 56,2 56,3 56,4 56,5 56,6 Simon, C.; Daniel, R. (2010). "Metagenomic Analyses: Past and Future Trends". Applied and Environmental Microbiology 77 (4): 1153–1161. PMC 3067235. PMID 21169428. doi:10.1128/AEM.02345-10.
- ↑ Willner, D; RV Thurber; F Rohwer (2009). "Metagenomic signatures of 86 microbial and viral metagenomes.". Environmental Microbiology 11 (7): 1752–66. PMID 19302541. doi:10.1111/j.1462-2920.2009.01901.x.
- ↑ Ghosh, Tarini Shankar; Monzoorul Haque Mohammed; Hannah Rajasingh; Sudha Chadaram; Sharmila S Mande (2011). "HabiSign: a novel approach for comparison of metagenomes and rapid identification of habitat-specific sequences.". BMC Bioinformatics 12 (Supplement 13): S9. PMC 3278849. PMID 22373355. doi:10.1186/1471-2105-12-s13-s9.
- ↑ Fimereli, D.; Detours, V.; Konopka, T. (13 February 2013). "TriageTools: tools for partitioning and prioritizing analysis of high-throughput sequencing data". Nucleic Acids Research 41 (7): e86. PMC 3627586. PMID 23408855. doi:10.1093/nar/gkt094.
- ↑ Maillet, Nicolas; Lemaitre, Claire; Chikhi, Rayan; Lavenier, Dominique; Peterlongo, Pierre (2012). "Compareads: comparing huge metagenomic experiments". BMC Bioinformatics 13 (Suppl 19): S10. PMC 3526429. PMID 23282463. doi:10.1186/1471-2105-13-S19-S10.
- ↑ Bhusan, Kuntal Kumar; Tarini Shankar Ghosh; Sharmila S Mande (2013). "Community-analyzer: a platform for visualizing and comparing microbial community structure across microbiomes". Genomics 102 (4): 409–418. PMID 23978768. doi:10.1016/j.ygeno.2013.08.004.
- ↑ Werner, Jeffrey J.; Dan Knights; Marcelo L. Garcia; Nicholas B. Scalfone; Samual Smith; Kevin Yarasheski; Theresa A. Cummings; Allen R. Beers; Rob Knight; Largus T. Angenent (8 March 2011). "Bacterial community structures are unique and resilient in full-scale bioenergy systems". Proceedings of the National Academy of Sciences of the United States of America 108 (10): 4158–4163. Bibcode:2011PNAS..108.4158W. ISSN 0027-8424. PMC 3053989. PMID 21368115. doi:10.1073/pnas.1015676108.
- ↑ McInerney, Michael J.; Jessica R. Sieber; Robert P. Gunsalus (December 2009). "Syntrophy in Anaerobic Global Carbon Cycles". Current Opinion in Biotechnology 20 (6): 623–632. ISSN 0958-1669. PMC 2790021. PMID 19897353. doi:10.1016/j.copbio.2009.10.001.
- ↑ Klitgord, N.; Segrè, D. (2011). "Ecosystems biology of microbial metabolism". Current Opinion in Biotechnology 22 (4): 541–546. PMID 21592777. doi:10.1016/j.copbio.2011.04.018.
- ↑ Leininger, S.; Urich, T.; Schloter, M.; Schwark, L.; Qi, J.; Nicol, G. W.; Prosser, J. I.; Schuster, S. C.; Schleper, C. (2006). "Archaea predominate among ammonia-oxidizing prokaryotes in soils". Nature 442 (7104): 806–809. Bibcode:2006Natur.442..806L. PMID 16915287. doi:10.1038/nature04983.
- ↑ 66,0 66,1 Kristensen, DM; Mushegian AR; Dolja VV; Koonin EV (2009). "New dimensions of the virus world discovered through metagenomics". Trends in Microbiology 18 (1): 11–19. PMC 3293453. PMID 19942437. doi:10.1016/j.tim.2009.11.003.
- ↑ Paez-Espino, D; Eloe-Fadrosh, EA; Pavlopoulos, GA; Thomas, AD; Huntemann, M; Mikhailova, N; Rubin, E; Ivanova, NN; Kyrpides, NC (25 August 2016). "Uncovering Earth's virome". Nature 536 (7617): 425–30. Bibcode:2016Natur.536..425P. PMID 27533034. doi:10.1038/nature19094.
- ↑ Paez-Espino, D; Chen, IA; Palaniappan, K; Ratner, A; Chu, K; Szeto, E; Pillay, M; Huang, J; Markowitz, VM; Nielsen, T; Huntemann, M; K Reddy, TB; Pavlopoulos, GA; Sullivan, MB; Campbell, BJ; Chen, F; McMahon, K; Hallam, SJ; Denef, V; Cavicchioli, R; Caffrey, SM; Streit, WR; Webster, J; Handley, KM; Salekdeh, GH; Tsesmetzis, N; Setubal, JC; Pope, PB; Liu, WT; Rivers, AR; Ivanova, NN; Kyrpides, NC (4 January 2017). "IMG/VR: a database of cultured and uncultured DNA Viruses and retroviruses.". Nucleic Acids Research 45 (D1): D457–D465. PMC 5210529. PMID 27799466. doi:10.1093/nar/gkw1030.
- ↑ Paez-Espino D, Roux S, Chen IA, Palaniappan K, Ratner A, Chu K, et al. (2018). "IMG/VR v.2.0: an integrated data management and analysis system for cultivated and environmental viral genomes". Nucleic Acids Res. 47 (D1): D678–D686. PMC 6323928. PMID 30407573. doi:10.1093/nar/gky1127.
- ↑ Paez-Espino, D; Pavlopoulos, GA; Ivanova, NN; Kyrpides, NC (August 2017). "Nontargeted virus sequence discovery pipeline and virus clustering for metagenomic data" (PDF). Nature Protocols 12 (8): 1673–1682. PMID 28749930. doi:10.1038/nprot.2017.063.
- ↑ Kerepesi, Csaba; Grolmusz, Vince (2016). "Giant Viruses of the Kutch Desert". Archives of Virology 161 (3): 721–724. PMID 26666442. arXiv:1410.1278. doi:10.1007/s00705-015-2720-8.
- ↑ Kerepesi, Csaba; Grolmusz, Vince (2017). "The "Giant Virus Finder" Discovers an Abundance of Giant Viruses in the Antarctic Dry Valleys". Archives of Virology 162 (6): 1671–1676. PMID 28247094. arXiv:1503.05575. doi:10.1007/s00705-017-3286-4.
- ↑ Copeland, CS (Sep-Oct 2017). "The World Within Us" (PDF). Healthcare Journal of New Orleans: 21–26.
- ↑ Jansson, Janet (2011). "Towards "Tera-Terra": Terabase Sequencing of Terrestrial Metagenomes Print E-mail". Microbe 6 (7). p. 309. Arquivado dende o orixinal o 31 de marzo de 2012. Consultado o 13 de decembro de 2019.
- ↑ Vogel, T. M.; Simonet, P.; Jansson, J. K.; Hirsch, P. R.; Tiedje, J. M.; Van Elsas, J. D.; Bailey, M. J.; Nalin, R.; Philippot, L. (2009). "TerraGenome: A consortium for the sequencing of a soil metagenome". Nature Reviews Microbiology 7 (4): 252. doi:10.1038/nrmicro2119.
- ↑ "TerraGenome Homepage". TerraGenome international sequencing consortium. Arquivado dende o orixinal o 07 de novembro de 2012. Consultado o 30 December 2011.
- ↑ 77,0 77,1 Committee on Metagenomics: Challenges and Functional Applications, National Research Council (2007). Understanding Our Microbial Planet: The New Science of Metagenomics (PDF). The National Academies Press. Arquivado dende o orixinal (PDF) o 30 de outubro de 2012. Consultado o 13 de decembro de 2019.
- ↑ Charles T (2010). "The Potential for Investigation of Plant-microbe Interactions Using Metagenomics Methods". Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN 978-1-904455-54-7.
- ↑ Bringel, Françoise; Couée, Ivan (22 May 2015). "Pivotal roles of phyllosphere microorganisms at the interface between plant functioning and atmospheric trace gas dynamics". Frontiers in Microbiology 6: 486. PMC 4440916. PMID 26052316. doi:10.3389/fmicb.2015.00486.
- ↑ Li, Luen-Luen; Sean R McCorkle; Sebastien Monchy; Safiyh Taghavi; Daniel van der Lelie (18 May 2009). "Bioprospecting metagenomes: glycosyl hydrolases for converting biomass". Biotechnology for Biofuels 2: 10. ISSN 1754-6834. PMC 2694162. PMID 19450243. doi:10.1186/1754-6834-2-10.
- ↑ Jaenicke, Sebastian; Christina Ander; Thomas Bekel; Regina Bisdorf; Marcus Dröge; Karl-Heinz Gartemann; Sebastian Jünemann; Olaf Kaiser; Lutz Krause; Felix Tille; Martha Zakrzewski; Alfred Pühler; Andreas Schlüter; Alexander Goesmann (26 January 2011). Aziz, Ramy K, ed. "Comparative and Joint Analysis of Two Metagenomic Datasets from a Biogas Fermenter Obtained by 454-Pyrosequencing". PLoS ONE 6 (1): e14519. Bibcode:2011PLoSO...614519J. PMC 3027613. PMID 21297863. doi:10.1371/journal.pone.0014519.
- ↑ Suen, Garret; Jarrod J Scott; Frank O Aylward; Sandra M Adams; Susannah G Tringe; Adrián A Pinto-Tomás; Clifton E Foster; Markus Pauly; Paul J Weimer; Kerrie W Barry; Lynne A Goodwin; Pascal Bouffard; Lewyn Li; Jolene Osterberger; Timothy T Harkins; Steven C Slater; Timothy J Donohue; Cameron R Currie (September 2010). Sonnenburg, Justin, ed. "An insect herbivore microbiome with high plant biomass-degrading capacity". PLoS Genetics 6 (9): e1001129. ISSN 1553-7404. PMC 2944797. PMID 20885794. doi:10.1371/journal.pgen.1001129.
- ↑ Simon, C.; Daniel, R. (2009). "Achievements and new knowledge unraveled by metagenomic approaches". Applied Microbiology and Biotechnology 85 (2): 265–276. PMC 2773367. PMID 19760178. doi:10.1007/s00253-009-2233-z.
- ↑ Wong D (2010). "Applications of Metagenomics for Industrial Bioproducts". Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN 978-1-904455-54-7.
- ↑ 85,0 85,1 Schloss, Patrick D; Jo Handelsman (June 2003). "Biotechnological prospects from metagenomics" (PDF). Current Opinion in Biotechnology 14 (3): 303–310. ISSN 0958-1669. PMID 12849784. doi:10.1016/S0958-1669(03)00067-3. Arquivado dende o orixinal (PDF) o 04 de marzo de 2016. Consultado o 3 January 2012.
- ↑ 86,0 86,1 86,2 Kakirde, Kavita S.; Larissa C. Parsley; Mark R. Liles (1 November 2010). "Size Does Matter: Application-driven Approaches for Soil Metagenomics". Soil Biology & Biochemistry 42 (11): 1911–1923. ISSN 0038-0717. PMC 2976544. PMID 21076656. doi:10.1016/j.soilbio.2010.07.021.
- ↑ Parachin, Nádia Skorupa; Marie F Gorwa-Grauslund (2011). "Isolation of xylose isomerases by sequence- and function-based screening from a soil metagenomic library". Biotechnology for Biofuels 4 (1): 9. ISSN 1754-6834. PMC 3113934. PMID 21545702. doi:10.1186/1754-6834-4-9.
- ↑ Hover BM, Kim S, Katz M, Charlop-Powers Z, Owen JG, Ternei MA, et al. (12 February 2018). "Culture-independent discovery of the malacidins as calcium-dependent antibiotics with activity against multidrug-resistant Gram-positive pathogens". Nature Microbiology 3 (4): 415–422. PMC 5874163. PMID 29434326. doi:10.1038/s41564-018-0110-1.
- ↑ Raes, J.; Letunic, I.; Yamada, T.; Jensen, L. J.; Bork, P. (2011). "Toward molecular trait-based ecology through integration of biogeochemical, geographical and metagenomic data". Molecular Systems Biology 7: 473. PMC 3094067. PMID 21407210. doi:10.1038/msb.2011.6.
- ↑ Lavery, T. J.; Roudnew, B.; Seymour, J.; Mitchell, J. G.; Jeffries, T. (2012). Steinke, Dirk, ed. "High Nutrient Transport and Cycling Potential Revealed in the Microbial Metagenome of Australian Sea Lion (Neophoca cinerea) Faeces". PLoS ONE 7 (5): e36478. Bibcode:2012PLoSO...736478L. PMC 3350522. PMID 22606263. doi:10.1371/journal.pone.0036478.
- ↑ "What's Swimming in the River? Just Look For DNA". NPR.org. 24 July 2013. Consultado o 10 October 2014.
- ↑ George I; et al. (2010). "Application of Metagenomics to Bioremediation". Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN 978-1-904455-54-7.
- ↑ Zimmer, Carl (13 July 2010). "How Microbes Defend and Define Us". New York Times. Consultado o 29 December 2011.
- ↑ Nelson KE and White BA (2010). "Metagenomics and Its Applications to the Study of the Human Microbiome". Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN 978-1-904455-54-7.
- ↑ Qin, Junjie; Ruiqiang Li; Jeroen Raes; Manimozhiyan Arumugam; Kristoffer Solvesten Burgdorf (March 2010). "A human gut microbial gene catalogue established by metagenomic sequencing". Nature 464 (7285): 59–65. Bibcode:2010Natur.464...59.. PMC 3779803. PMID 20203603. doi:10.1038/nature08821.
Véxase tamén editar
Outros artigos editar
Ligazóns externas editar
- Focus on Metagenomics na páxina web da revista Nature Reviews Microbiology
- The “Critical Assessment of Metagenome Interpretation” (CAMI) iniciativa para avaliar os métodos da metaxenómica